写在前面:
本程序的底层框架采用PyQt自主编写, 学习部分基于Sklearn, 多目标优化框架基于Pymoo。 实验和经验发现对于表格类数据, 传统机器学习具有相比于深度学习方法更高的精度和更快的速度。因此在子方法中没有MLP等深度学习方法, 未来可能会加入GANs或者Diffusion Model等方法进行数据扩充。
主要服务目标关键词为:混凝土优化, 混凝土配合比, 多目标优化
欢迎所有的bug反馈, 尤其是特殊报错的时候, 前提是你的步骤是对的。
如何掌握报错信息和进行反馈:
一般可能会发生的错误, 例如数据没导入就进行分析, 导入数据格式不一致, 都进行了弹出提示框的对应。此外任何步骤顺利进行完之后都会有相应的提示。
但是毕竟Bug千奇百怪, 我的能力也有限, 因此软件底层加入了python的traceback机制, 用以完全掌握报错的信息和来源。 如果你在运行软件的过程中, 报错框为红色且一堆英文, 或者再日志信息处出现了报错信息。那么大概说明这类报错属于比较特殊的报错, 且一般和数据本身存在关系, 包括但不限于除数为0等等。
如果你有代码基础, 看得懂或者知道如何搜索这些报错的解决方法, 那么最好。如果无法解决, 可以通过联系方式向我进行反馈。
总览:
程序的目录脑图如下图所示:

整体流程图如下图所示:
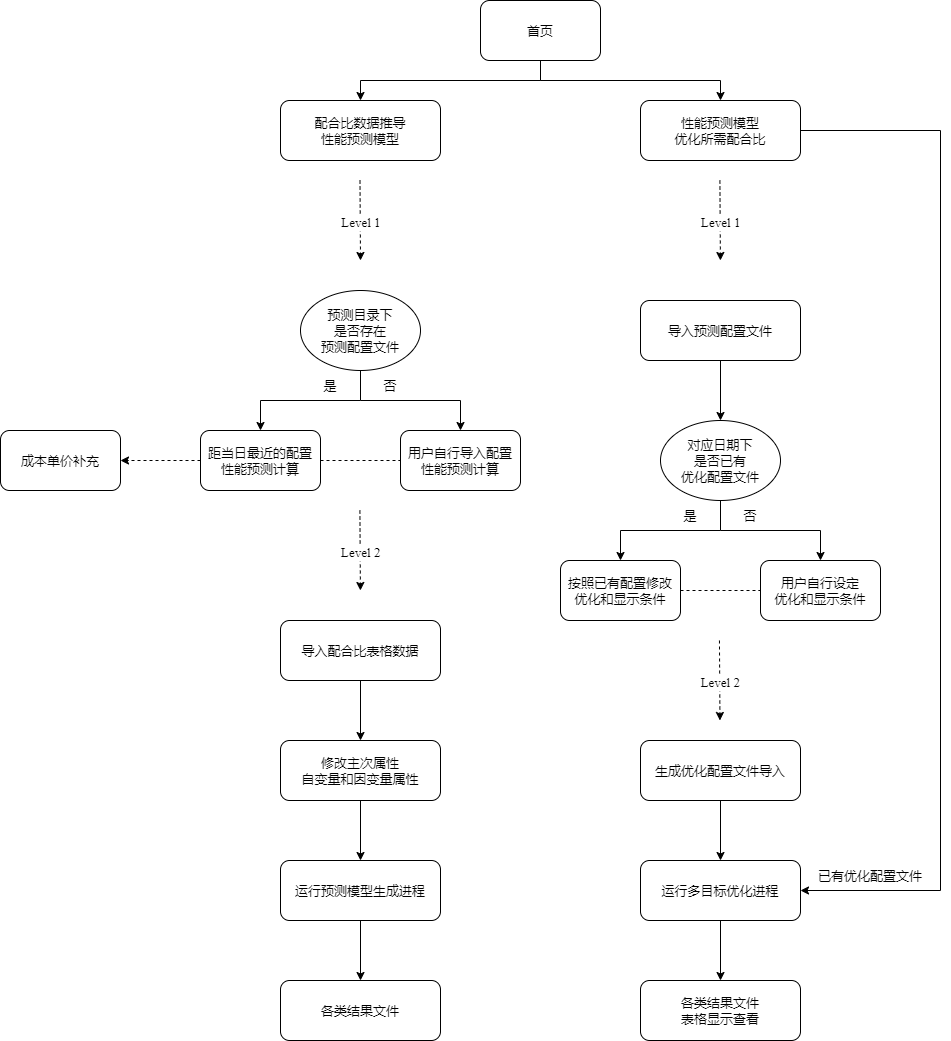
所有文件的路径(绝对路径)不能有中文和特殊符号。
请注意, 在接下来的所有描述中, 我们将 x 视作自变量组分的集合(例如水/水泥/粉煤灰等), y 视作目标参数的集合(例如抗压强度/流动度/抗氯离子侵蚀性等, 包括用户自定义的函数)
首页界面:
如下图所示
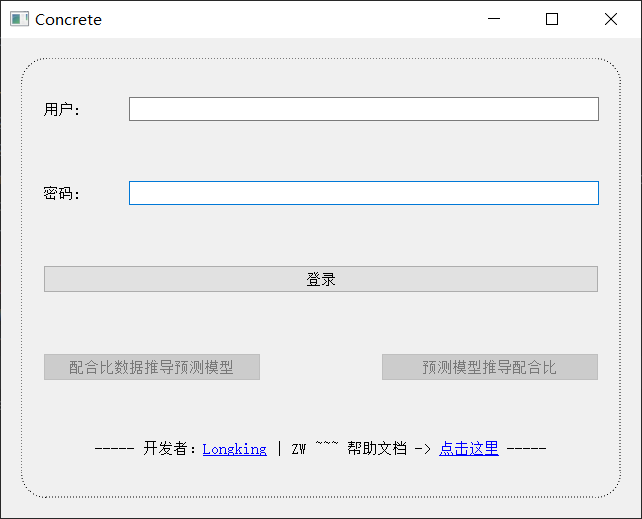
点就完事儿
第一个程序:
该程序的主要流程是: 一级窗口(左侧)进行已有预测模型的计算测试; 二级窗口(右侧)导入原始表格文件, 进行每一个标签的预测模型的求解
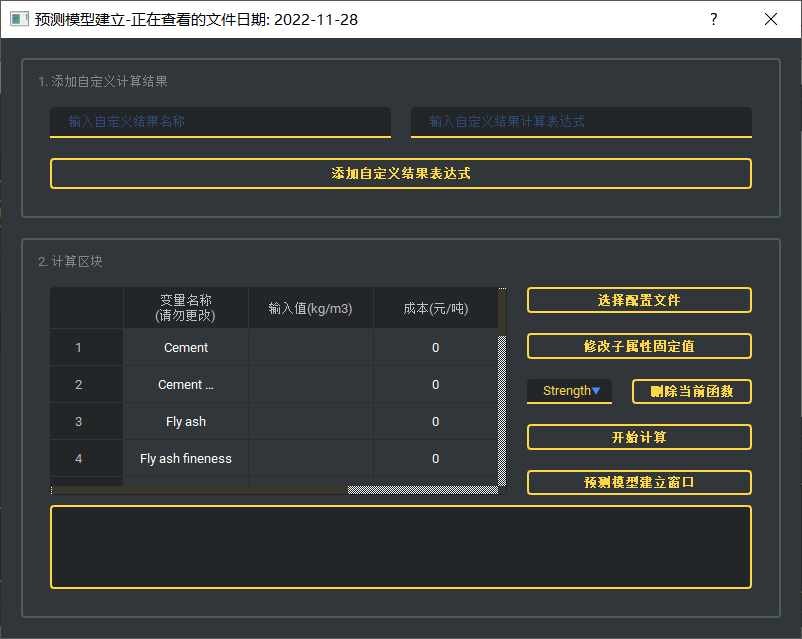
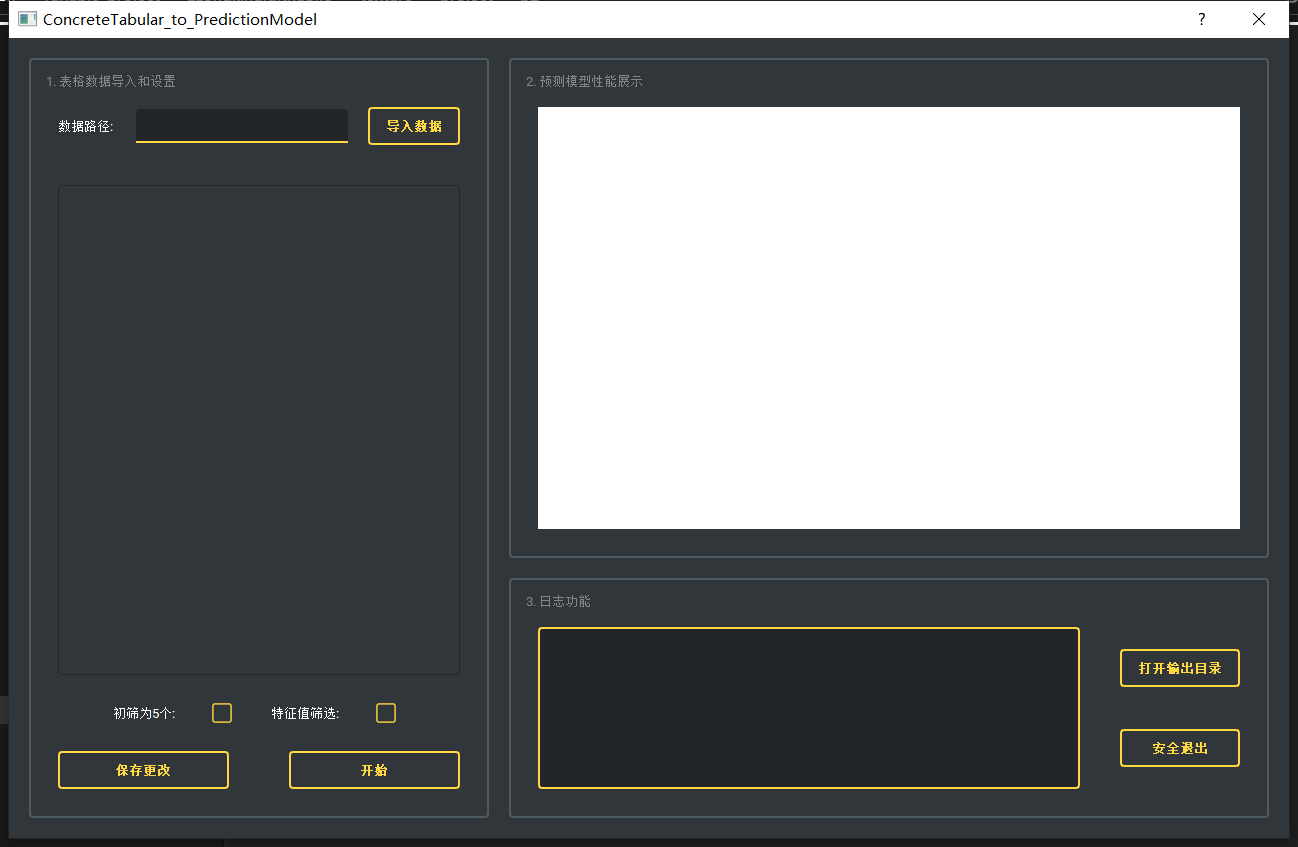
- 一级窗口 ==> 已有预测模型, 配置文件测试
- 一级窗口 ==> 添加自定义计算表达式
- 一级窗口 ==> 输入数据并进行预测和计算
- 二级窗口 ==> 读取文件(支持xlsx, xls和csv三种格式)
- 修改表格各类值的主次属性和变量属性
- 二级窗口 ==> 运行构建预测模型流程
- filter_xx.xlsx ==> 表示经过初筛步骤后的各算法在该标签数据上的基本指标。
- {$model_name$}_{$label_name$}_{$date$}.pkl ==> 表示基于model_name的算法模型, 得到的预测label_name的预测模型。
- {$label$}.png ==> 性能展示图的文件保存。
- pre_cfg.json ==> 预测模型构建过程中, 关于该数据集的所有重要信息的文件, 也是多目标优化流程中所需要的关键基础。
- pre_log.txt ==> 在软件界面控制台所显示内容的记录, 若勾选了特征值筛选选项, 则在关闭软件后, 该日志是唯一记录了最佳特征组合的信息来源。
- xxx.png ==> 各种图片, 包括优化结果图, 参数热力图, 特征权重直方图。若勾选了特征值筛选选项, 还会生成一份根据递归特征消除法所得到的, 前n个特征所建立模型的R2折线图。
- 打开输出目录
- 安全退出
打开窗口时, 存在两种状态:
若在 output/predcition/{$date$}/ 文件夹下存在任意一个已经经过由本程序的预测模型建立过程所得到的结果, 则该窗口会默认导入距离本日期距离最近的此类结果的配置文件 pre_cfg.json。若没有任何文件夹满足该类条件, 则会保持空状态, 子属性窗口也无法打开。此时需要用户自行导入某一配置文件再进行下面的步骤。 导入文件的日期可见窗口上方横栏。
在左侧文本行输入你想得到的某表达式结果的名称, 例如水灰比, 水胶比等; 右侧输入表达式。之后点击添加即可。
表达式书写格式请见这里
计算时, 自变量分为两部分: 主属性和子属性。主属性和子属性的定义参照这里。 主属性在该窗口表格中, 子属性需点击 修改子属性固定值 进入修改。
在表格中填入对应的数据量值即可, 若想改变成本也可进行更改。之后在右侧的下拉框中选择你想要得到的预测目标(包括成本等自定义函数), 点击开始计算即可, 结果见下方文本栏。 需要注意的是, 本程序自动创建了成本预测函数作为自定义函数中的一个以供用户进行快捷设置。若你想保存该成本单价信息, 则需要运行一遍成本预测过程。
提示, 如果你的数据是文本文件且主要数据部分数据之间都是逗号隔开的形式, 可以通过直接更改后缀的形式强制转化为.csv
注意, 这里所导入的文件的规范为: 第一行为x或y的名称, 从第二行开始每一行即为一组数据。 若某一类数据的值为非数字, 则程序会默认将其进行数字编码。 不需要将x和y分成两个进行导入, 仅支持合并。
示例如下所示:
| 水泥 | 水 | 粉煤灰 | 机制砂 | ... | 抗压强度 | 流动度 |
| ... | ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... | ... |
| ... | ... | ... | ... | ... | ... | ... |
若先前已经经过该窗口处理过, 可直接导入 output/prediction/{$date$}/edit.xlsx 文件, 省去修改时间
之后在第一部分的白框处将会显示一个简易表格, 需要用户在这里设置各个标签的属性, 共有三列。
该表格第一列为刚导入的表格数据中所包含的标签名称。第二、三列为需要用户进行设置的判断内容。
在第二列中, 如果你的数据中, 该项是x, 请将其设置为1; 若该项是y, 请将其设置为2; 若不需要该项参加优化过程(包括但不限于该项本身无用, 该项中的值在表格中恒定, 减少参数有利于加快进程), 请将其设置为0。
请注意, 若某一个y的计算方法为纯数学公式推导, 建议不要加入预测流程(设置为0)。
第三列为归属关系的表示, 例如当水泥(假设编号为1)的含量为0时, 无论水泥强度(假设编号为3)是425还是525都不会起到任何作用。 则需要用户进行设置, 表示水泥强度归属于水泥, 在需要进行归属关系设置的行的第三列处选择主属性即可 没有这类关系或者为主属性的标签请保持默认(该行标签本身)。 y中元素是没有主次属性之分的, 改了也没用。
之后点击保存, 弹出提示框即可。与此同时 {$dir_path$}/output/prediction/{$today$}/ 文件夹下将会生成一个 edit.xlsx, 今后若还需导入相同文件时导入它修改步骤将减少。
下方两个选项, 第一个表示: 默认情况下是在验证集上依据R2得到前三个算法进入优化, 若勾选第一个选项则会改成5个(与此同时所花费时间会变长)。
第二个表示, 若勾选该选项, 假设该数据X中共有t个特征, 则在每一个Y所得到的预测模型生成后, 会额外依据特征权重(若为线性模型则为分项系数)从大到小的顺序, 依次单独拿取前n个特征, 依照该预测算法通过递归特征消除法另外进行t次相同步骤并计算此时在测试集上的R2。请注意, 该子流程并不会选择最好的组合保存模型, 考虑到第二部分多目标优化, 这里仅在日志中显示哪些特征组合会得到最好的预测效果, 并通过图片(自动保存)的形式进行大致展示。若希望按照该特征组合获得相应的模型, 请按照上述流程剔除掉多余的特征并重新运行程序。
以上步骤完成后, 点击开始, 预测模型推理线程将会启动。在第三个区域的文本框中将会实时进行线程进度的更新, 同时若发生报错也将会进行对应的打印。 对于y中的每一个元素来说, 当预测模型建立完毕后, 第二区域中画板将会出现在测试集上该预测模型的性能展示。
当文本框中出现 "全部流程结束, 用时 xxx min" , 则说明流程完成。与此同时 {$dir_path$}/output/prediction/{$today$}/ 文件夹下将会生成六类文件, 分别是:
点击即可
由于程序以子线程方式存在, 因而推荐以安全退出按钮进行程序的退出, 防止因为预测模型构建流程未完毕强制退出而造成的程序卡死。
第二个程序:
该程序的主要流程是: 导入已经完成的预测文件夹或已经处理好的多目标优化配置文件, 进行多目标优化流程。
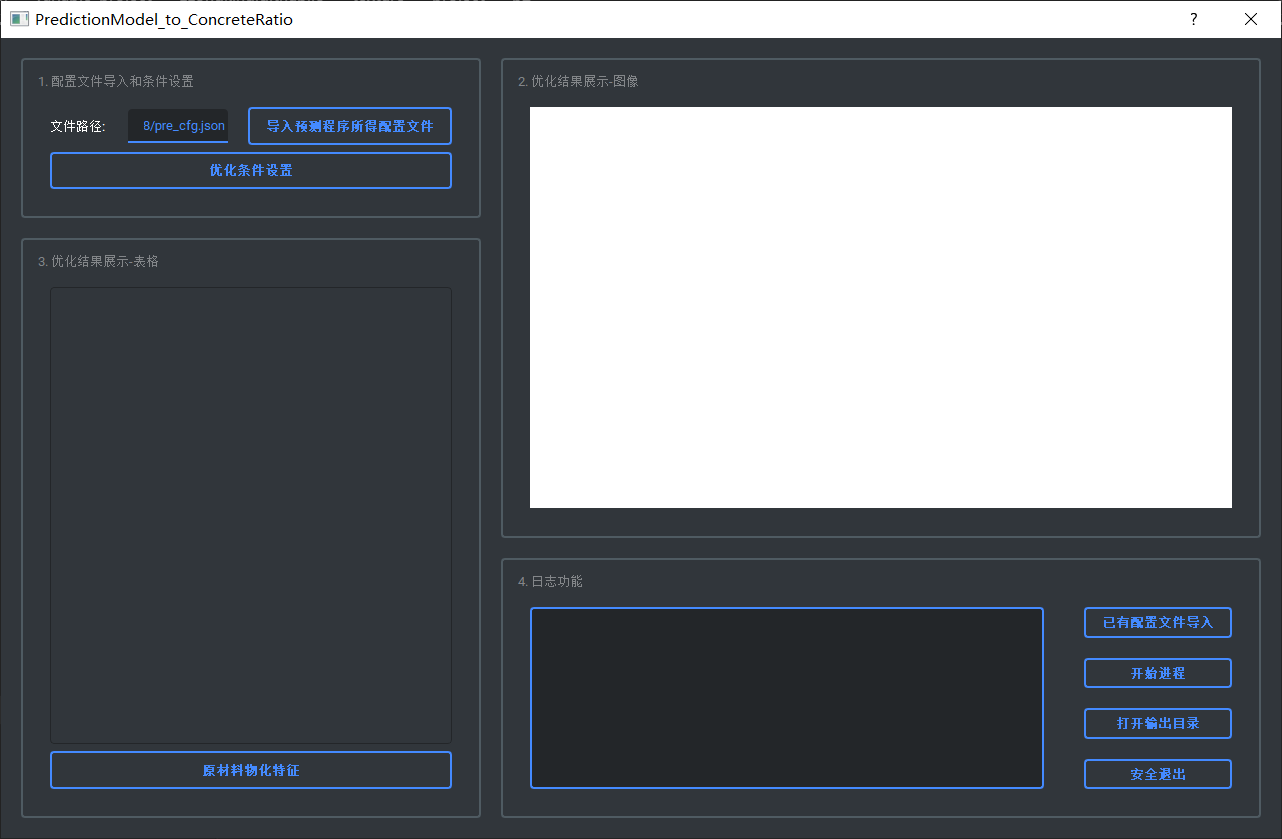
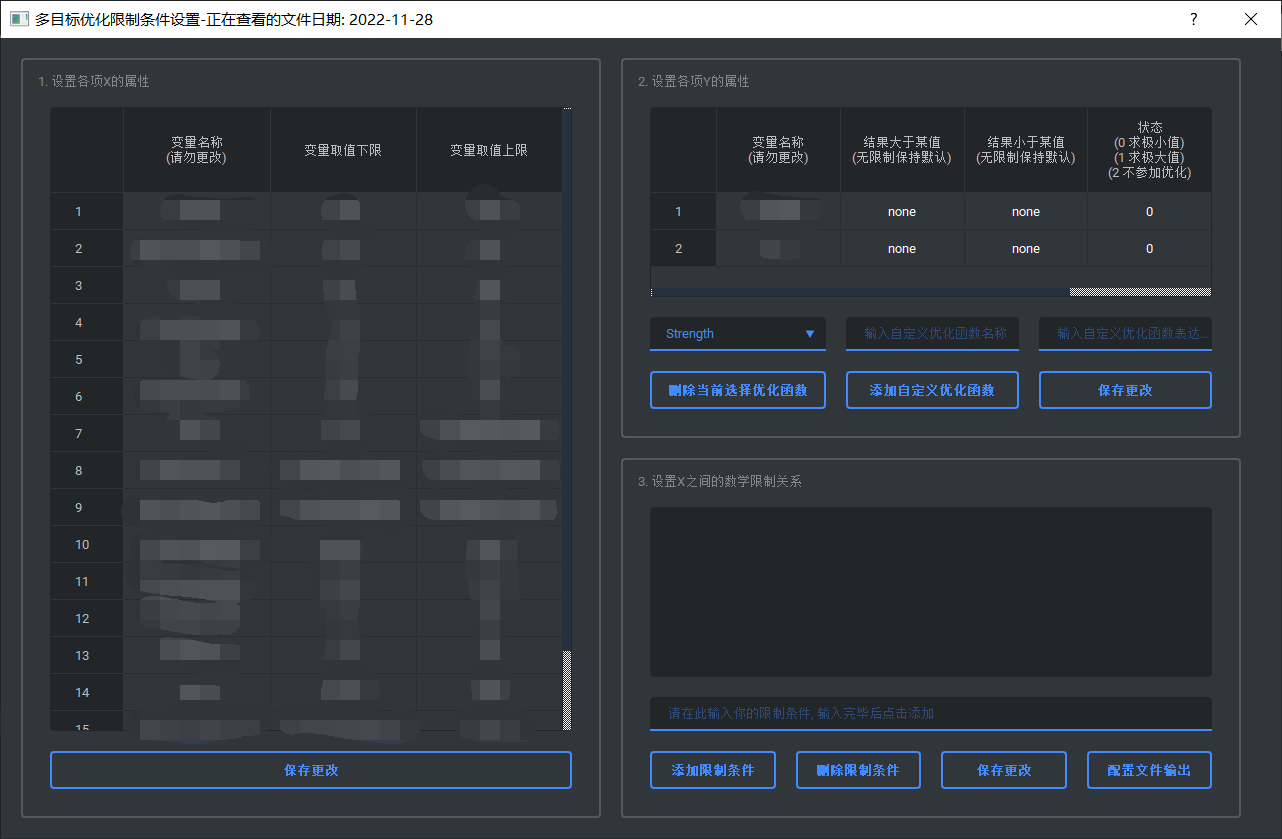
- 预测模型配置文件导入
- 优化条件设置 ==> 设定x的上下界
- 优化条件设置 ==> 自定义y优化结果
- 设定x中各元素之间的制约关系(表达式书写方法)
- 已经有了配套的多目标优化配置文件
- 开始运行
- 安全退出
即第一个程序中所得到的配置文件pre_cfg.json。不允许导入moo_cfg.json。
导入后即可点击下方的"优化条件设置"按钮进入条件设置界面。详见右图排布。 请注意, 若你导入的文件为 output/prediction/date-special/pre_cfg.json , 则此时系统会自动寻找是否存在 output/moo/date-special/moo_cfg.json。若存在则优化条件设定窗口的默认状态将遵从此moo_cfg中所保存的配置。 若数据本身不同, 或不想遵从moo_cfg.json里的配置。则需要手动删除 output/moo/date-special/moo_cfg.json (请勿删除文件夹), 建议有一个备份的习惯, 需要的时候再挪进来。
在第一部分中, 所生成的表格共有三列。
第一列为x的各组分名称, 第二三列为用户所需要设置的x中各个元素的优化上下界(指最终所得出的优化结果中, x不会超过这个区间)。 如果你希望某一个x元素是定值, 则在两列中填入相同的值即可。 默认为原数据中各个x元素的最大最小值。
修改完后注意点击保存
第二部分的表格结构和第一部分相近
比如我们希望最终优化出来的混凝土抗压强度大于50MPa, 则可以在相应最小值处填入50, 最大值处保持默认即可
默认值为无穷小和无穷大(none)
但是相比于第一部分而言多了一列, 用来规定对于y中某元素来说, 我们希望它得到的结果时越小越好还是越大越好。 例如对于成本来说, 自然是希望越便宜越好, 这个时候就可以在最后一栏填写0; 对于强度来说, 我们希望它越大越好, 即填写1。
若此目标值不参加优化过程, 仅起到一个限定作用或只想在最后的结果输出时查看该项属性, 则在最后一栏填写2。
另外本部分支持添加自定义优化函数, 例如成本函数。函数表达式编写方法参考这里
修改完后注意点击保存
由于算法本身并不知道某些客观事实, 比如水灰比, 水胶比, 砂率含水率的限制等, 需要引入人为的先验知识进行限制。
若想引入限制条件, 则需要按一定的格式在下方长条的文本栏中输入文字, 输入完后点击 "添加限制条件" , 机会在上方的列表中显示出来。
格式为:
其中value1和value2表示表达式的上下界, value1和value2至少要有一个存在且可以为0, 不能使用大于等于号。
Expression(X(i) or Y(i))表示以X(i)和Y(i)为核心的数学表达式, XY必须为大写, 括号必须为英文括号。
关于Expression(X(i) or Y(i)), 举个例子, 如果你想要让水和水泥的比例在0.15到0.4之间, 并且在同页面的表格中, 水对应的序号是1, 水泥对应的序号是4, 则:
0.15<=X(1)/X(4)<=0.4
另外一个例子, 如果你想让水和沙子加石子的比例大于0.2且上不封顶, 水的序号是1, 沙子的序号是6 ,石子的序号是7, 则:
0.2<=X(1)/(X(6)+X(7))
而Y(i)则表示预测模型构建中, 第i个预测值, 且不包含自定义优化函数。例如在构建预测模型时, 预测目标值是强度和流动度, 并且在后面又加入了成本, 水灰比等自定义目标值。 这里的i就为, 第二部分的优化函数设置表格的对应序号, 且i在本例子中只许取1和2。表达式书写规范同上。
另外, 依据实践经验, 约束条件不可设置的太严或者太宽松。太严会导致求解空间极小, 往往没有足够的space去适应和迭代。 太宽松的话没有良好的约束, 得出的结果虽然符合需求, 但不一定会符合客观事实。
如果你想删除某个已经编辑好的条件, 则只需在列表中选中该条件后, 点击删除条件按钮即可
全部设置完毕后, 注意需事先保存前两步的处理结果后, 先点击 "保存更改",后点击"配置文件输出" 按钮。 (因为这个时候如果你没有按三个保存, 是无法进行输出的)。 会在{$dir_path$}/output/moo/{$today$}/ 文件夹生成moo_cfg.json文件(软件底层此时并没有保存), 供主程序使用。
完成后回到主程序
此时点击 "已有配置文件导入" , 直接找到对应的moo_cfg.json文件即可。
点击按钮, 和第一个程序相同, 运行日志已经相关报错信息将会出现在最后一个部分左侧的文本框中。结果绘图在第二个区域中。
完毕后最后在{$dir_path$}/output/moo/{$today$}/ 文件夹生成两个文件, 一个为优化后的各个x结果, 另一个为其对应的y。同时在左侧的展示表格中会显示主属性和目标值的优化结果。 点击 原材料物化性质 显示对应的子属性结果, 每行一一对应。 请注意, 由于算法内部变量空间为连续值, 所以尽管某些自变量在第一部分设置的是固定值, 结果仍然会出现微小浮动, 为正常情况。
由于程序以子线程方式存在, 因而推荐以安全退出按钮进行程序的退出, 防止因为流程未完毕强制退出而造成的程序卡死。
结尾:
整套软件代码量3000余行, 代码部分由我一人独立完成, 理论和数据验证部分由我和师兄共同完成。希望各位用的顺心。